
Hi folks,
Tomorrow’s meeting will be an opportunity for you all to help me out with the bioinformatics page!
Oh, you go, what fun that sounds… but I do want to get your input on what content to put in it. I’m happy to fill it in, but it’s to be our public face and no doubt you have opinions of value.
In case you can’t make it to the meeting, and to maybe get you thinking about it now, I’m just going to paste in some images from the current site, which is not live, to give you an idea of what it looks like so far:
[cid:C302208D-0403-43F6-B79D-E319E6BA7E89@maths.utas.edu.au][cid:E16040A2-4F72-4D50-9DE2-CEBD11688C1B@maths.utas.edu.au][cid:36FB9CD3-5499-47B8-AFE3-1DF6746B4AA5@maths.utas.edu.au] and here’s some text:
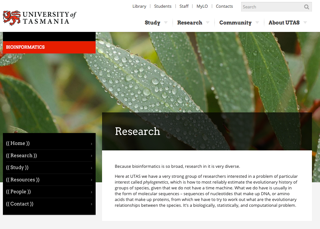
Research
Because bioinformatics is so broad, research in it is very diverse.
Here at UTAS we have a very strong group of researchers interested in a problem of particular interest called phylogenetics, which is how to most reliably estimate the evolutionary history of groups of species, given that we do not have a time machine. What we do have is usually in the form of molecular sequences – sequences of nucleotides that make up DNA, or amino acids that make up proteins, from which we have to try to work out what are the evolutionary relationships between the species. It's a biologically, statistically, and computational problem.
Study
If you're interested in learning about bioinformatics, there are several options open to you.
One of the most obvious is the University unit, Introduction to Bioinformaticshttp://www.utas.edu.au/courses/set/units/kma712-bioinformatics. This 700-level unit introduces research students to some of the techniques and concepts that underpin usingbioinformatics in the Life Sciences. It helps you get to grips with using the command-line (or terminal) to run programs on remote machines, such as in the Cloud. It exposes you to some of the key challenges in bioinformatics, from the computational complexity of assembling a genome and the fastest ways to find matching DNA sequences in a database, to the statistical difficulty of dealing with many thousands of tests and accounting for thousands of potential false positives.
There are also many potential research projects in, or using, bioinformatics – in understanding how gene activity varies with different conditions, or how bio-molecules evolve, or how much gene flow there is between different eucalypts. The best way to find out what projects we're currently pursuing is by contacting some of us – go to the Contacts page for details.
It’s very much a draft as you can see, and I’d love some suggestions of what other kinds of things you’d like to see on the site. I’d like to add a page of external links and contacts we have for those who are connected in some way with UTAS bioinformatics – e.g., funding bodies – but not officially part of UTAS, and I’d like to include a list of PhD projects. Clearly also a link to this very mailing list would be useful.
If all that takes only a short while then I’ll give a completely spontaneous talk on cophylogenetics. I have a suspicion I coined this term but you can google it if you don’t know..
Cheers, see you tomorrow!
Mike
Michael Charleston Associate Professor in Bioinformatics School of Physical Sciences University of Tasmania AUSTRALIA phone: +61 3 6226 2444
University of Tasmania Electronic Communications Policy (December, 2014). This email is confidential, and is for the intended recipient only. Access, disclosure, copying, distribution, or reliance on any of it by anyone outside the intended recipient organisation is prohibited and may be a criminal offence. Please delete if obtained in error and email confirmation to the sender. The views expressed in this email are not necessarily the views of the University of Tasmania, unless clearly intended otherwise.
{kind=link}
{kind=link}
{kind=link}